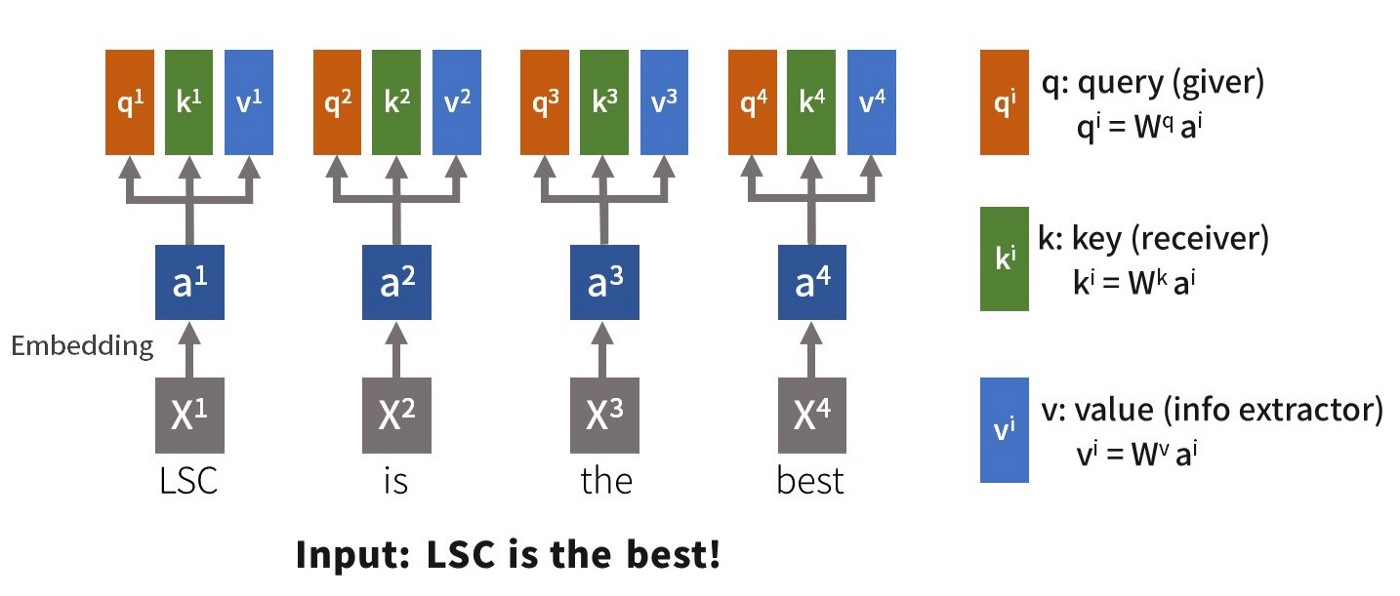
1 摘要
背景:
- 本文的核心思想来自于认知科学领域经常讨论的人类感知的两种互惠机制:自下而上(从视网膜到视觉皮层 - 局部元素和显着刺激分层组合在一起形成整体)处理和 自上而下(围绕全局上下文、选择性注意和先验知识为特定的解释提供信息)处理;
- 过去十年在计算机视觉领域取得巨大成功的卷积神经网络并没有反映视觉系统的这种双向性质。相反,它的前馈传播只是通过从原始感觉信号建立更高的抽象表示来模拟自下而上的处理;
- CNN 的局部感受野和刚性计算会使得 CNN 缺乏对全局上下文的理解,这样会导致许多问题:
- 模型难以建立和捕捉长期依赖关系;
- 缺乏对全局形状和结构形成整体理解的能力;
- 优化和训练稳定性问题,如 GAN 模型普遍存在难训练的问题,因为在生成图像的精细细节之间的协调存在着固有的困难。
- 需要新型模型来缓解上述问题。
核心思想: