数据预处理分析,最后面附有决策树算法的实现
原始数据:
原数据地址
计算第一次决策如果
分别对在14天各个属性下是否进行施肥的统计情况且计算该属性的基尼指数,同一种属性不同表现的基尼指数表示为M,加权平均之后为节点的基尼指数,用N表示
天气:
1 | #encoding = utf-8 |
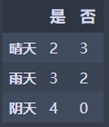
晴天:M1 = 2 2/5 (1 - 2/5) = 0.444444445
雨天:M2 = 2 3/5 (1 - 3/5) = 0.48
阴天:M3 = 0
N1 = 5/14 M1 + 5/14 M2 = 0.343
温度:
1 | Hot = Base_file[Base_file['温度'] == '炎热']['是否施肥'].value_counts() |
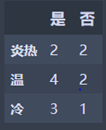
炎热:M1 = 2 2/4 (1 - 2/4) = 0.5
温 : M2 = 2 2/6 (1 - 2/6) = 0.44444445
冷: M3 = 2 3/4 (1 - 3/4) = 0.375
N2 = 4/14 M1 + 6/14 M2 + 4/14 * M3 = 0.440
湿度:
1 | Humidity_high = Base_file[Base_file['湿度'] == '高']['是否施肥'].value_counts() |
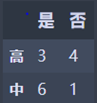
高:M1 = 2 3/4 (1 - 3/4) = 0.375
中:M2 = 2 6/7 (1 - 6/7) = 0.245
N3 = 1/2 M1 + 1/2 M2 = 0.310
风力:
1 | Wind_strong = Base_file[Base_file['风力'] == '强风']['是否施肥'].value_counts() |
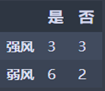
强风:M1 = 2 3/6 (1 - 3/6) = 0.5
弱风:M2 = 2 6/8 (1 - 6/8) = 0.375
N4 = 6/14 M1 + 8/14 M2 = 0.429
因为N2 > N4 > N1 > N3,所以第一次决策应根据湿度来分类:
因为此次分类之后,然未出现叶子节点,所以需要分别对第二排的两个节点进行分类,过程与第一次决策类似,计算各个属性下是否进行施肥的统计情况且计算该属性的基尼指数
左右节点的数据分别如下:
1 | Base_file = pd.read_excel('Data.xlsx') |

先对左边节点分析:
天气:
1 | Weather_Sunny = Temperature_df_high[Temperature_df_high['天气'] == '晴天']['是否施肥'].value_counts() |
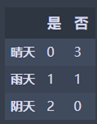
晴天:M1 = 0
雨天:M2 = 0.5
阴天:M3 = 0
N1 = 2/7 * M2 = 0.143
温度:
1 | Hot = Temperature_df_high[Temperature_df_high['温度'] == '炎热']['是否施肥'].value_counts() |
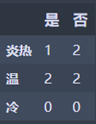
炎热:M1 = 0.44444444445
温: M2 = 0.5
冷: M3 = 0
N2 = 3/7 M1 + 4/7 M3 = 0.476
风力:
1 | Wind_strong = Temperature_df_high[Temperature_df_high['风力'] == '强风']['是否施肥'].value_counts() |
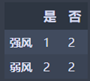
强风:M1 = 0.44444444445
弱风:M2 =0.5
N3 = 3/7 M1 + 4/7 M2 = 0.476
N1 > N2 = N3
所以左边的节点来说应该根据天气情况来分类
对右边节点分析:
天气:
1 | Weather_Sunny = Temperature_df_mid[Temperature_df_mid['天气'] == '晴天']['是否施肥'].value_counts() |
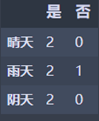
晴天:M1 = 0
雨天:M2 = 0.444444444445
阴天:M3 = 0
N1 = 3/7 * M2 = 0.190
温度:
1 | Hot = Temperature_df_mid[Temperature_df_mid['温度'] == '炎热']['是否施肥'].value_counts() |
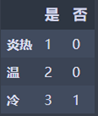
炎热:M1 = 0
温: M2 = 0
冷: M3 = 2 3/4 (1 - 3/4) = 0.375
N2 = 3/7 * M3 = 0.214
风力:
1 | Wind_strong = Temperature_df_mid[Temperature_df_mid['风力'] == '强风']['是否施肥'].value_counts() |
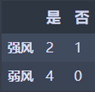
强风:M1 = 2 2/3 (1 - 2/3) = 0.44444445
弱风:M2 = 0
N3 = 3/7 * M2 = 0.190
N1 = N3 > N2
这里可以有两种分类决策方法,这里选择使用天气属性对右边节点进行分类,结合对左边节点的分析,对第二层的分类如下:
经过第二次分类之后,出现了叶子节点,只剩下两个节点需要继续分类,且只剩下温度和风力两个属性,下面是第二次分类之后的左右两个节点数据:
1 | Weather_df_Rainy1 = Base_file[Base_file['湿度'] == '高'][Base_file['天气'] == '雨天'] |
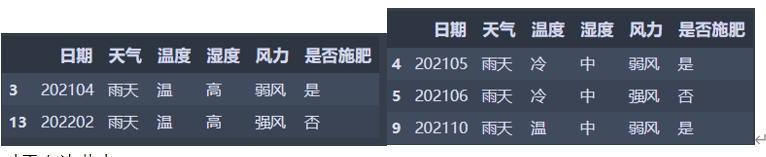
对于左边节点:
温度:
1 | Hot = Weather_df_Rainy1[Weather_df_Rainy1['温度'] == '炎热']['是否施肥'].value_counts() |

炎热:M1 = 0
温: M2 = 2 1/2 (1 – 1/2) = 0.5
冷: M3 = 0
N1 = M2 = 0.5
风力:
1 | Hot = Weather_df_Rainy1[Weather_df_Rainy1['温度'] == '炎热']['是否施肥'].value_counts() |
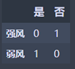
强风:M1 = 0
弱风:M2 = 0
N2 = 0
N1 > N2
所以左边的节点应用风力属性继续往后分类
对右边节点分析:
温度:
1 | Hot = Weather_df_Rainy2[Weather_df_Rainy2['温度'] == '炎热']['是否施肥'].value_counts() |
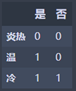
炎热:M1 = 0
温: M2 = 0
冷: M3 = 2 1/2 (1 – 1/2) = 0.5
N1 = M3 = 0.5
风力:
1 | Wind_strong = Weather_df_Rainy2[Weather_df_Rainy2['风力'] == '强风']['是否施肥'].value_counts() |
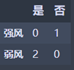
强风:M1 = 0
弱风:M2 = 0
N2 = 0
N1 > N2
所以右边边的节点应用风力属性继续往后分类,决策图如下:
可以看出第二次分类再经过风力的分类之后,此时决策树最后一排的节点全部变为了叶子节点,说明至此,分类完成。
算法实现:
1 | #encoding = utf-8 |
