一、数据集
数据集介绍
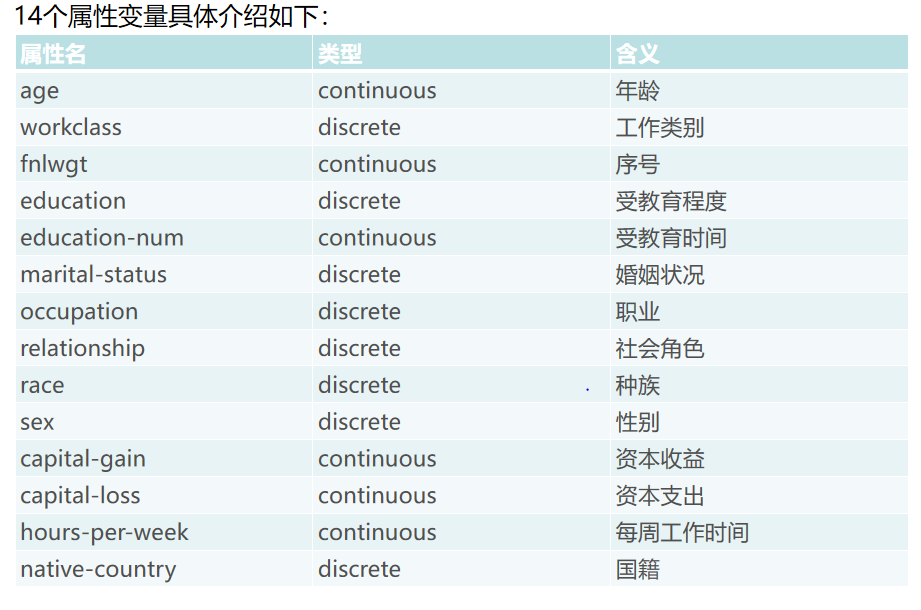
Adult数据集是一个经典的数据挖掘项目的的数据集,该数据从美国1994年人口普查数据库中抽取而来,因此也称作“人口普查收入”数据集,共包含48842条记录,年收入大于 50k 的占比23.93%年收入小于 50k 的占比76.07%,数据集已经划分为训练数据32561条和测试数据16281条。该数据集类变量为年收入是否超过 50k ,属性变量包括年龄、工种、学历、职业等14类重要信息,其中有8类属于类别离散型变量,另外6类属于数值连续型变量。该数据集是一个分类数据集,用来预测年收入是否超过50k。下载地址点这里。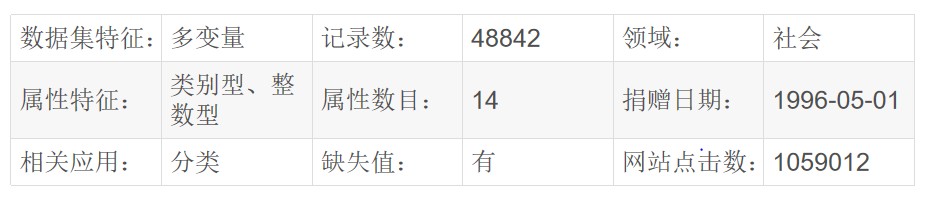
数据集预处理及分析
因为是csv数据,所以主要采用pandas和numpy库来进行预处理,首先数据读取以及查看是否有缺失:
1 | import pandas as pd |
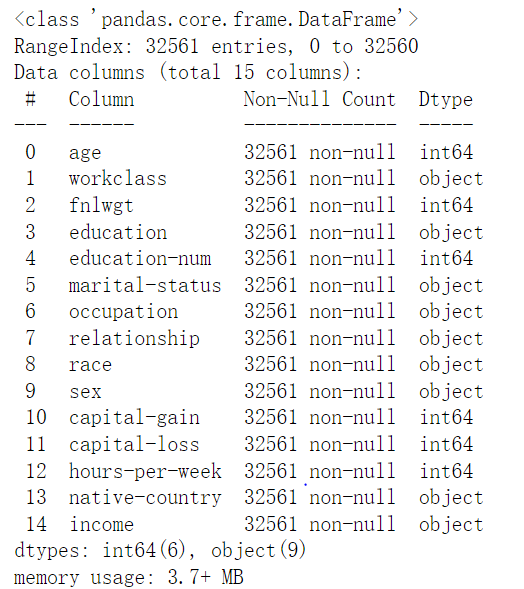
虽然上面查看数据是没有缺失值的,但其实是因为缺失值的是” ?”,而info()检测的是NaT或者Nan的缺失值。注意问号前面还有空格。
1 | df.apply(lambda x : np.sum(x == " ?")) |

分别是居民的工作类型workclass(离散型)缺1836、职业occupation(离散型)缺1843和国籍native-country(离散型)缺583。离散值一般填充众数,但是在此之前要先将缺失值转化成nan或者NaT。同时因为收入可以分为两种类型,则将>50K的替换成1,<=50K的替换成0。
1 | df.replace(" ?", pd.NaT, inplace = True) |
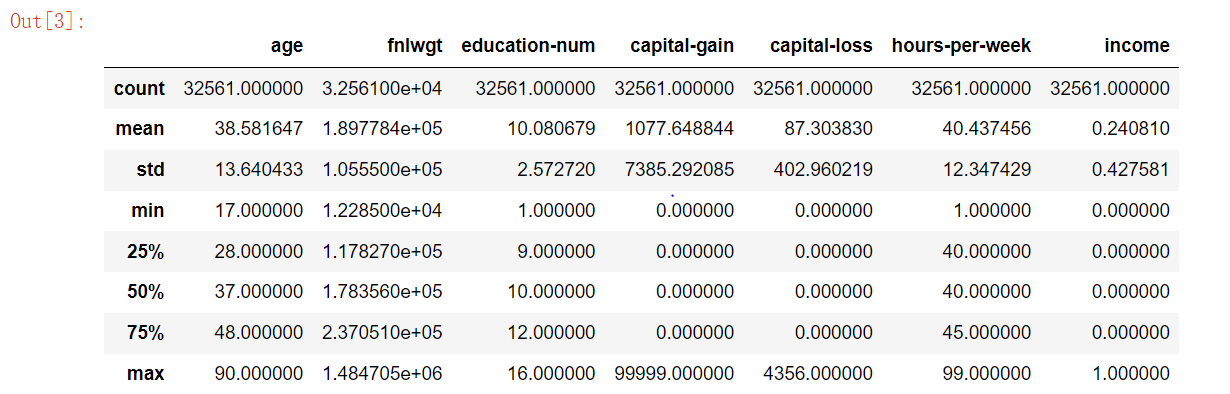
由上表可知,75%以上的人是没有资本收益和资本输出的,所以这两列是属于无关属性的,此外还包括序号列,应删除这三列。所以我们只需关注这三列之外的数据即可。
1 | df.drop('fnlwgt', axis = 1, inplace = True) |

1 | import matplotlib.pyplot as plt |
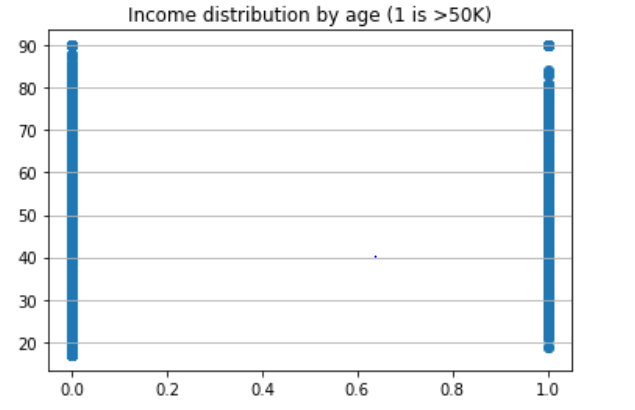
能看出对于中高年龄的人来说收入>50K是比<=50K的少。
1 | df["workclass"].value_counts() |
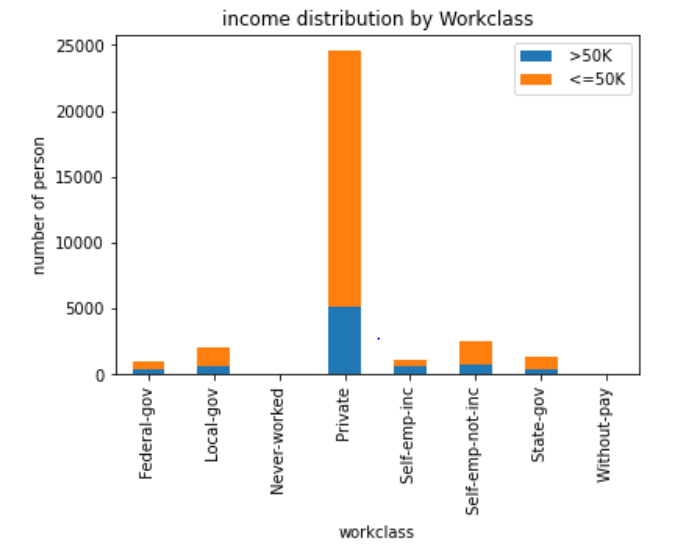
观察工作类型对年收入的影响。工作类别为Private的人在两种年收入中都是最多的,但是>50K和<=50K的比例最高的是Self-emp-inc。
1 | df1 = df["hours-per-week"].groupby(df["workclass"]).agg(['mean','max','min']) |
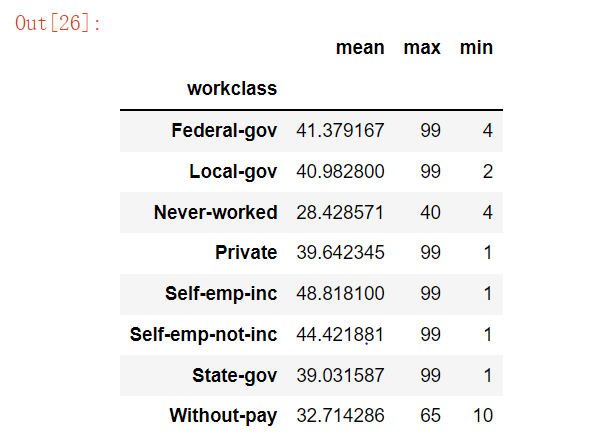
用工作类别对每周工作时间进行分组,计算每组的均值,最大、小值,并且按均值进行排序。能看出工作类别是Federal-gov的人平均工作时间最长,但其的高收入占比并不是最高的。
1 | income_0 = df["education"][df["income"] == 0].value_counts() |
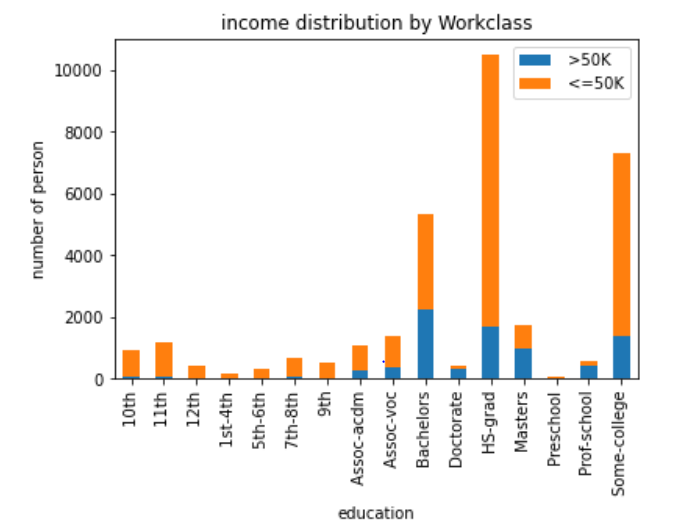
统计受教育程度对年收入的影响,对于程度是Bachelors来说,两种收入的人数是比较接近的,收入比也是最大的。
1 | income_0 = df["education-num"][df["income"] == 0] |
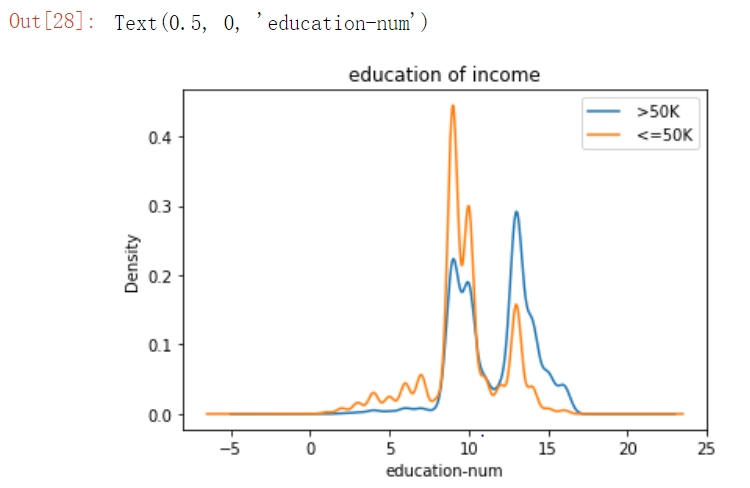
统计受教育时间对收入的影响的概率密度图。大约在时间的中值的时段,收入>50K的人是比<=50K的概率要低一些,而在中值偏右的时段是相反的,在其余时段,两种收入大约是处于平衡的状态。
1 | # fig, ([[ax1, ax2, ax3], [ax4, ax5, ax6]]) = plt.subplots(2, 3, figsize=(15, 10)) |
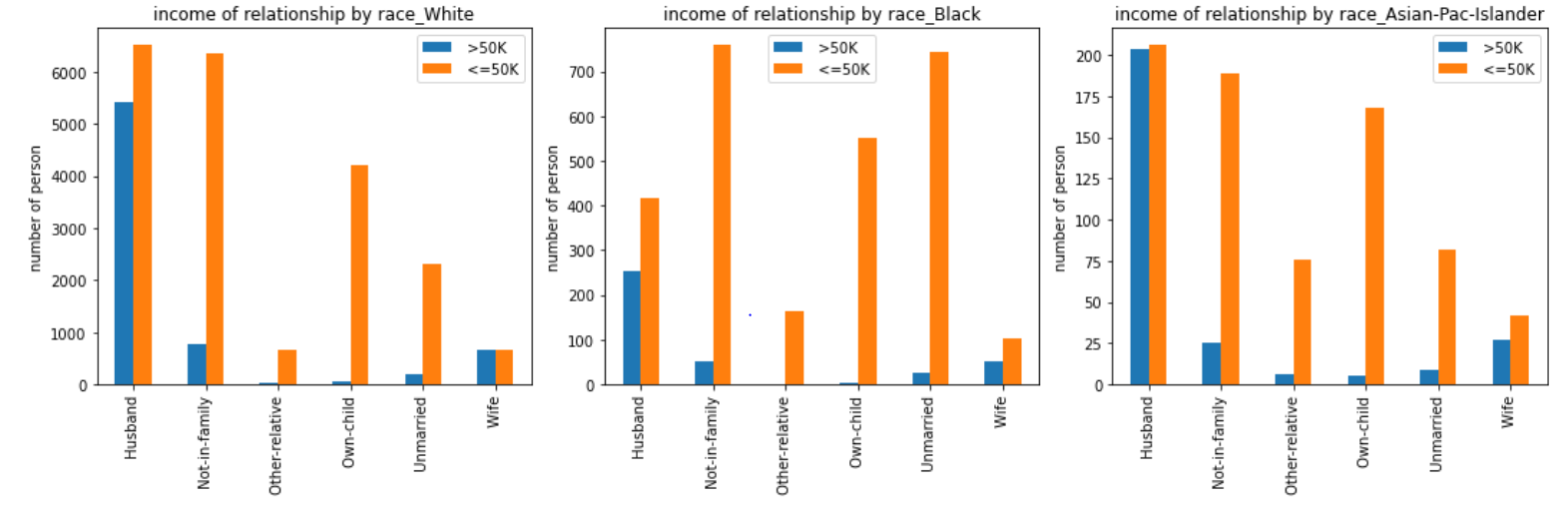
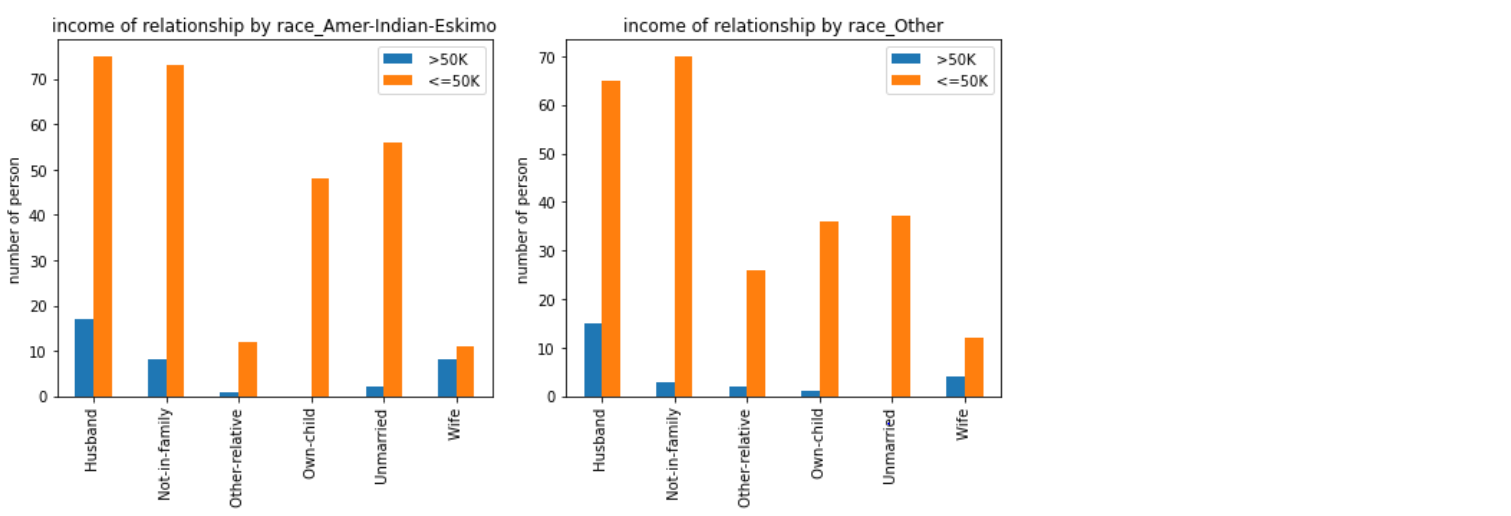
这里主要是做了不同种族扮演的社会角色的收入状况。
1 | # fig, ([[ax1, ax2, ax3], [ax4, ax5, ax6]]) = plt.subplots(2, 3, figsize=(10, 5)) |
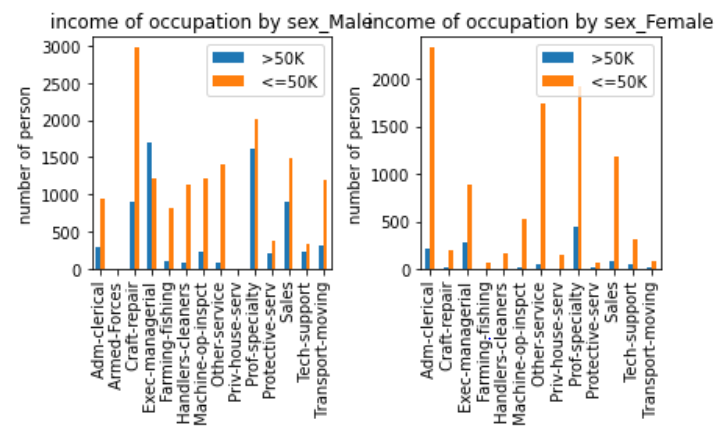
这里主要是做了不同性别的职业的收入状况。在男性中,职业为Exec-managerial的人中,收入>50K的人要比<=50K的人要多,而这种情况在女性中刚好相反。
1 | df_object_col = [col for col in df.columns if df[col].dtype.name == 'object'] |
先对数据类型进行统计,对非数值型的数据进行独热编码,再将两者进行拼接。最后将收入与其他数据分开分别作为标签和训练集或者测试集。
二、四种模型对上述数据集进行预测
深度学习
导入相关包
1 | import pandas as pd |
数据预处理,要注意的是训练集和测试集进行独热编码之后可能形状不一样,所以要将他们进行配对;再者是因为我们要给缺失某列的数据进行增加全为零的列,奇怪的是当从DataFrame类型转到Numpy类型时全为零的列会全部变成nan,所以还要重新nan的列转成零。否则在预测的过程网络的输出会全部为nan。本次实验将训练集进行2 : 8的数据划分,2份作为验证集。且要对数据集进行归一化,效果会好很多。
1 | def add_missing_columns(d, columns) : |
构建网络,因为是简单的二分类,这里使用了两层感知机网络,后面做对结果进行softmax归一化。
1 | class Adult_Model(nn.Module) : |
训练及验证,每经过一个epoch,就进行一次损失比较,当val_loss更小时,保存最好模型,直至迭代结束。
1 | device = torch.device('cuda' if torch.cuda.is_available() else "cpu") |
下载在训练过程保存的最好模型进行预测并保存结果:
1 | best_model = Adult_Model().to(device) |
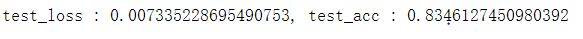
正确率达到0.834还是蛮不错的。
决策树
数据处理,跟深度学习的过程基本一致,只是返回值不一样而已。
1 | import pandas as pd |
GridSearchCV 类可以用来对分类器的指定参数值进行详尽搜索,这里搜索最佳的决策树的深度。
1 | # params = {'max_depth' : range(1, 20)} |
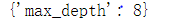
用决策数进行分类,采用‘熵’作为决策基准,决策深度由上步骤得到8,分裂一个节点所需的样本数至少设为5,并保存预测结果。
1 | # clf = DecisionTreeClassifier() score:0.7836742214851667 |
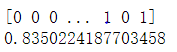
结果有0.835跟深度学习差不多,可视化决策树结构:
1 | dot_data = export_graphviz(clf, out_file = None, feature_names = columns, class_names = classes, filled = True, rounded = True) |

支持向量机
因数据处理方式与决策树相同,这里不再张贴,只粘贴模型部分。
1 | from sklearn import svm |
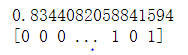
随机森林
1 | classes = [' <=50K', ' >50K'] |
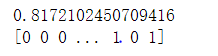
三、结果分析
经过在Adult数据集的测试集的预测结果可知,深度学习模型、决策树、支持向量机和随机森林的正确率分别达到0.834、0.834、0.834和0.817,四种模型的正确率差不多。正确率并不是很高的原因可能有:
1、模型的鲁棒性不够。
2、数据集存在大量的离散类型数据,在经过独热编码之后,数据高度稀疏。
解决方法:
1、对模型再进行搜索性地调参,可以考虑增加模型复杂度,过程中需要注意过拟合。
2、不选择独热编码的方式对数据进行降维,可以考虑Embedding
所有的代码都可以从我的 Github仓库 获取,欢迎您的start
最后,如果您对Adult数据集的处理和模型实现有收获的话,还要麻烦给点个赞,不甚感激。