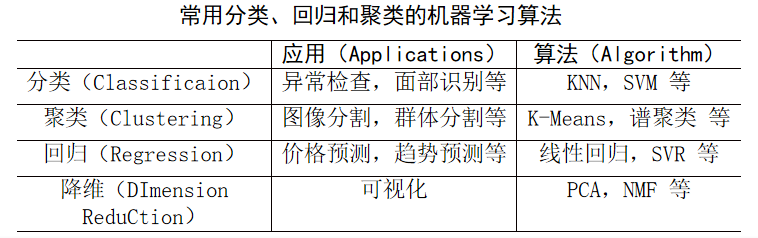
1 scikit-learn介绍
scikit-learn与机器学习的关系:
- Scikit-learn是基于Python语言的第三方机器学习库。它包含了几乎所有主流机器学习算法的实现,并提供一致的调用接口。
- Scikit-learn基于 NumPy 和 SciPy 等科学计算库,支持支持向量机、随机森林、梯度提升树、K 均值、聚类等机器学习算法。
scikit-learn功能:
- Scikit-learn (简记sklearn)是当今非常流行的机器学习工具,也是最有名的Python机器学习库。
- Scikit-learn主要功能包括分类、回归、聚类、数据降维、模型选择和数据预处理六大部分。
2 scikit-learn常用模块
2.1 数据集模块
如果要使用Scikit-learn库中提供的数据集,要通过from sklearn import dataset导入数据集模块。
loaders可用来加载小的标准数据集,如dataset.load_irisfetchers可用来下载并加载大的真实数据集,如dataset.fetch_olivetti_faces
loaders和fetchers的所有函数都返回一个字典一样的对象,里面至少包含两项:shape为n_samples*n_features的数组,对应的字典key是data以及长度为n_samples的numpy数组,包含了目标值,对应的字典key是target。通过将return_X_y参数设置为True,几乎所有这些函数都可以将输出约束为只包含特征和标签的元组。
generation functions可以用来生成受控的合成数据集(synthetic datasets),这些函数返回一个元组(X,y),该元组由shape为n_samples*n_features的numpy数组X和长度为n_samples的包含目标y的数组组成。
2.2 数据预处理模块
Scikit-learn的sklearn.preprocessing模块中提供了数据标准化、规范化、二值化、分类特征编码、推断缺失数据等数据预处理方法,通过from sklearn import preprocessing导入。

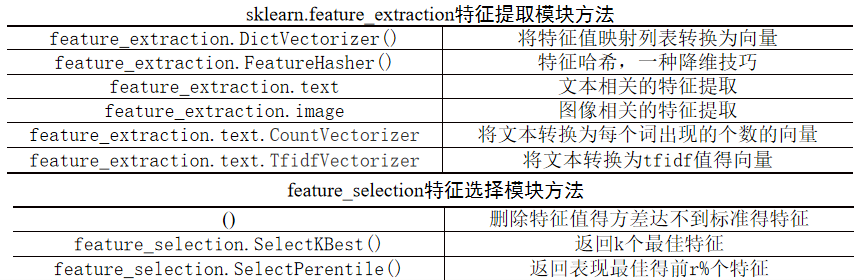
2.3 特征提取与选择模块
特征提取是数据预处理任务中重要的一个环节。特征提取对最终结果的影响要高过数据处理算法本身,通过from sklearn import feature_extraction (特征提取)和from sklearn import feature_selection (特征选择)导入。
3 K邻近算法(K-Nearest Neighbor, KNN)介绍
基本思想:给定一个训练数据集,对新输入的样本,在训练数据集中找到与该样本最邻近的k个实例(也就是所谓的k个邻居),这k个实例中的多数属于某个类别,就把输入样本划分到该类别中。k近邻算法通常又可以分为分类算法和回归算法。
- 分类算法中采用多数表决法,就是选择k个样本中出现最多的类别标记作为预测结果。
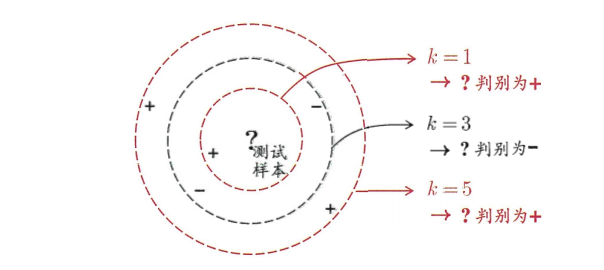
- 回归算法中采用平均法,将k个样本实际输出标记的平均值或加权平均值作为预测结果。
优点:准确性高,对异常值和噪声有较高的容忍度。同时应用广泛,不论是分类还是回归都可以使用。
缺点:KNN是一种懒惰学习方法,在训练得是很好不是真正在学些什么,只是一字不差地存储训练数据。计算量较大,对内存要求也比较大。因为,每次对一个未标记样本进行分类时,都需要全部计算一遍距离。当数据样本分布不平衡时,对稀有类别的预测准确率较低。
4 KNN算法实现Iris数据集的分类
1 | import matplotlib.pyplot as plt |

从结果上我们能看出,n_neighbors 也就邻居的数量的选取的不同会影响最终的正确率,但他们之间不是简单的线性关系,n_neighbors 过大或过小都会增大噪声对模型的影响,可能会出现过度拟合的情况。常见做法是,n_neighbors 一般取奇数,尽量避免可能投票表决相等的情况。如上面的简单例子,模型在 n_neighbors 为$1、3、5$条件下表现得相对好一些。