1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| import cv2 as cv
import matplotlib.pyplot as plt
import numpy as np
%matplotlib
m1 = np.array([[5, 5, 5], [-3,0,-3], [-3,-3,-3]])
m2 = np.array([[-3, 5,5], [-3,0,5], [-3,-3,-3]])
m3 = np.array([[-3,-3,5], [-3,0,5], [-3,-3,5]])
m4 = np.array([[-3,-3,-3], [-3,0,5], [-3,5,5]])
m5 = np.array([[-3, -3, -3], [-3,0,-3], [5,5,5]])
m6 = np.array([[-3, -3, -3], [5,0,-3], [5,5,-3]])
m7 = np.array([[5, -3, -3], [5,0,-3], [5,-3,-3]])
m8 = np.array([[5, 5, -3], [5,0,-3], [-3,-3,-3]])
filterlist = [m1, m2, m3, m4, m5, m6, m7, m8]
filtered_list = np.zeros((8, img_clean.shape[0], img_clean.shape[1]))
for k in range(8) :
out = cv.filter2D(img_clean, cv.CV_16S, filterlist[k])
filtered_list[k] = out
final = np.max(filtered_list, axis = 0)
final[ np.where(final >= 255)] = 255
final[ np.where(final < 255) ] = 0
fig = plt.figure(figsize = (10, 5))
fig.set(alpha = 0.2)
plt.subplot2grid((1, 2), (0, 0))
plt.imshow(img_clean, 'gray')
plt.subplot2grid((1, 2), (0, 1))
plt.imshow(final, 'gray')
|
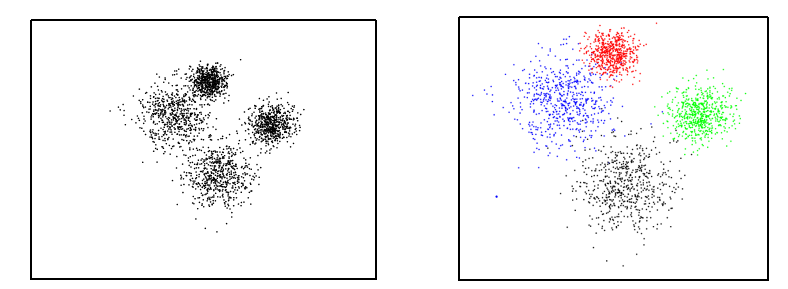








 算法步骤如下:
算法步骤如下: